 local.ai
local.aiLocal AI Management, Verification, & Inferencing.
Experiment with AI offline, in private. No GPU required! - A native app made to simplify the whole process.
Free and open-source.
Starting an inference session with the WizardLM 7B model in 2 clicks.
Power any AI app, offline or online. Here in tandem with window.ai.
Powerful Native App
With a Rust backend, local.ai is memory efficient and compact. (<10MB on Mac M2, Windows, and Linux .deb)
Available features:
- CPU Inferencing
- Adapts to available threads
- GGML quantization q4, 5.1, 8, f16
Upcoming features:
- GPU Inferencing
- Parallel session
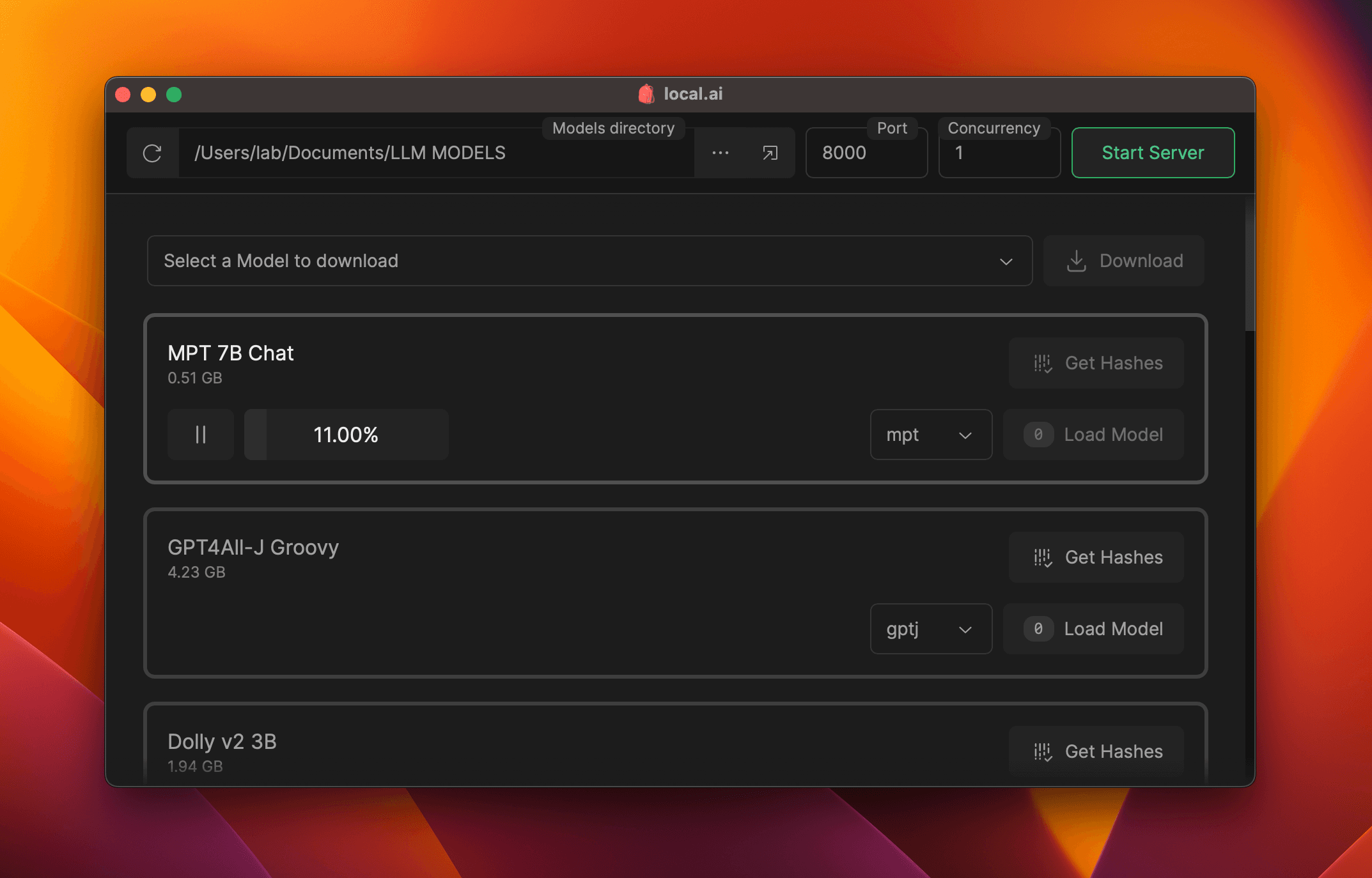
Model Management
Keep track of your AI models in one centralized location. Pick any directory!
Available features:
- Resumable, concurrent downloader
- Usage-based sorting
- Directory agnostic
Upcoming features:
- Nested directory
- Custom Sorting and Searching

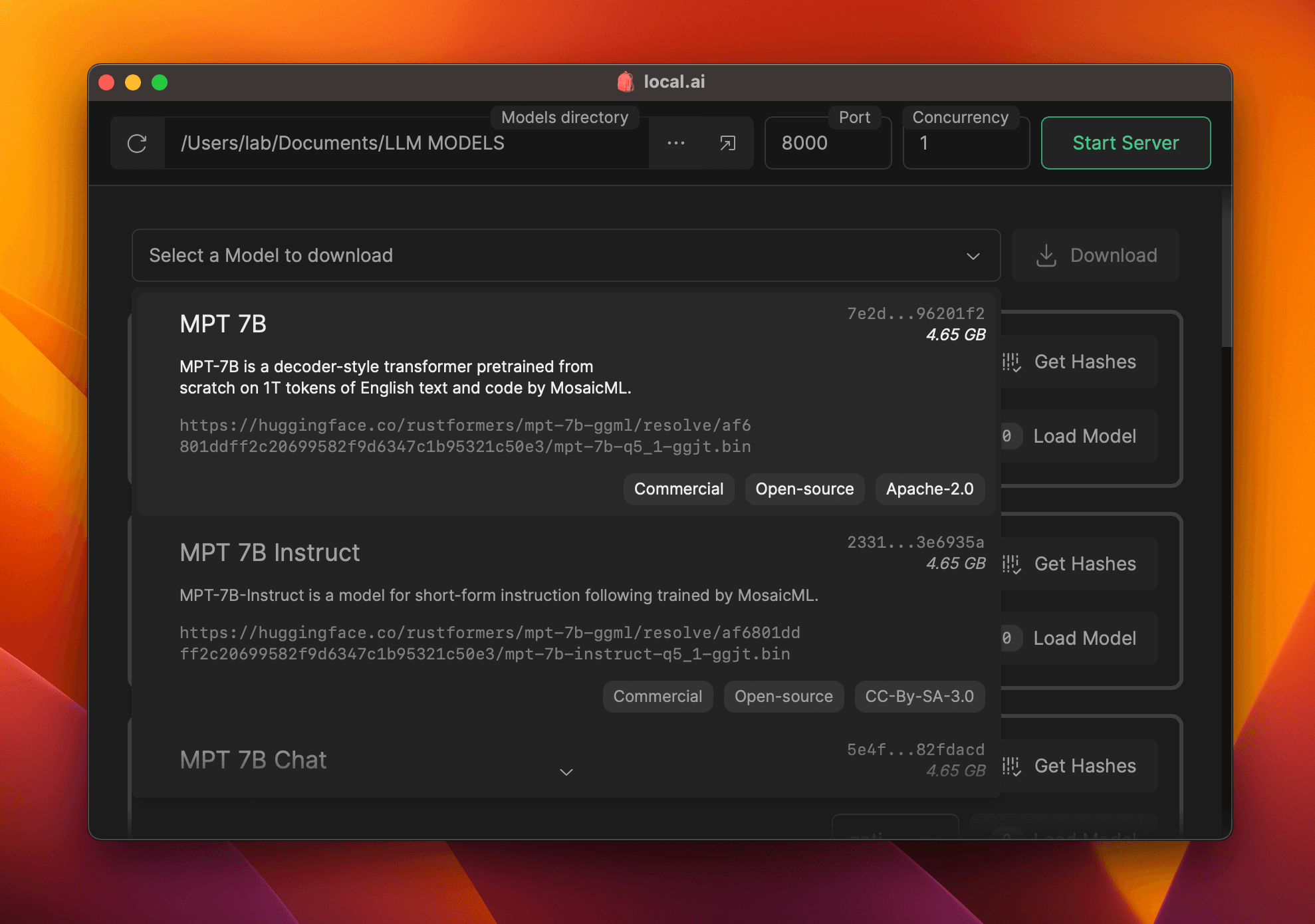
Digest Verification
Ensure the integrity of downloaded models with a robust BLAKE3 and SHA256 digest compute feature.
Available features:
- Digest compute
- Known-good model API
- License and Usage chips
- BLAKE3 quick check
- Model info card
Upcoming features:
- Model Explorer
- Model Search
- Model Recommendation
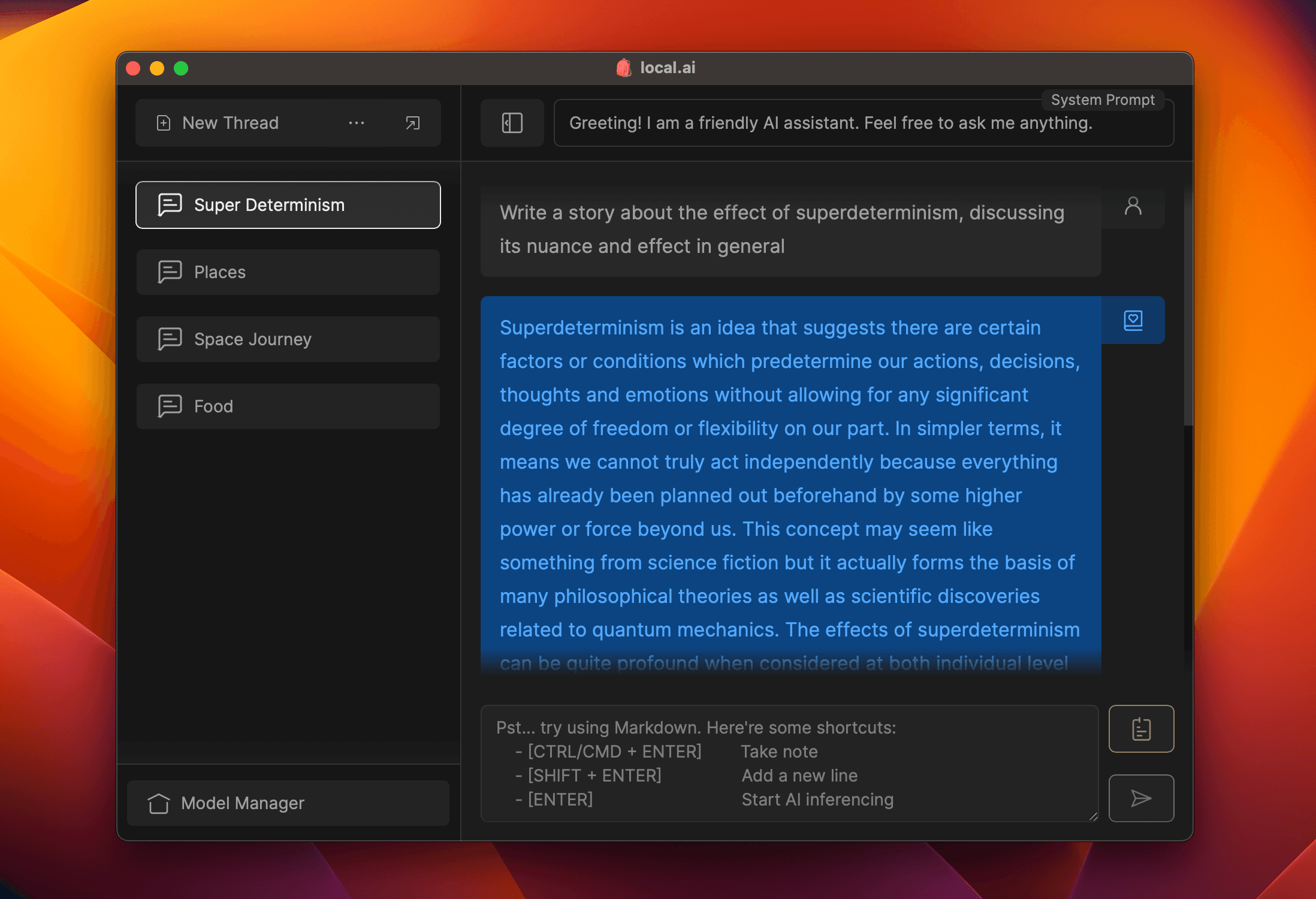
Inferencing Server
Start a local streaming server for AI inferencing in 2 clicks: Load model, then start server.
Available features:
- Streaming server
- Quick inference UI
- Writes to .mdx
- Inference params
- Remote vocabulary
Upcoming features:
- Server Managet
- /audio
- /image
